
Boosting Kubernetes Efficiency with Karpenter: 3-Month Performance Insights
Anastasis Vomvylas · September 9, 2024 · 7 min read
Karpenter is a Kubernetes nodes autoscaler designed to be simple, efficient, and cost-effective. At Autoscout24, we were using cluster-autoscaler before. In this blog post, I will share our observations and reflections after 3 months of using Karpenter in production.
Reasons for Switching to Karpenter
Before we dive into the impact of Karpenter, let’s first discuss why we decided to switch to Karpenter.
| Feature | Cluster-autoscaler | Karpenter |
|---|---|---|
| EC2 instance type | Static | Dynamic |
| AWS infrastructure definition | Needs Autoscaling Group definitions | Does not need any manual AWS infrastructure deployment |
| Graceful node shutdown | No | Built-in |
| Resource optimization | No | Optimizes for costs |
The main selling point for us was the cost optimization. Karpenter is designed to continuously optimize the cost of your Kubernetes cluster. It achieves this by moving resources (pods) around to maximize node resource utilization. More utilization means fewer nodes, which means less cost overall.
Migrating to Karpenter from cluster-autoscaler
I won’t go through the details of how to migrate from cluster-autoscaler to Karpenter, as Karpenter already provides great documentation which we followed.
The migration was smooth and low risk since it can be done gradually.
Observations After 3 Months
After using Karpenter for more than 3 months, we can share the following observations:
The Good
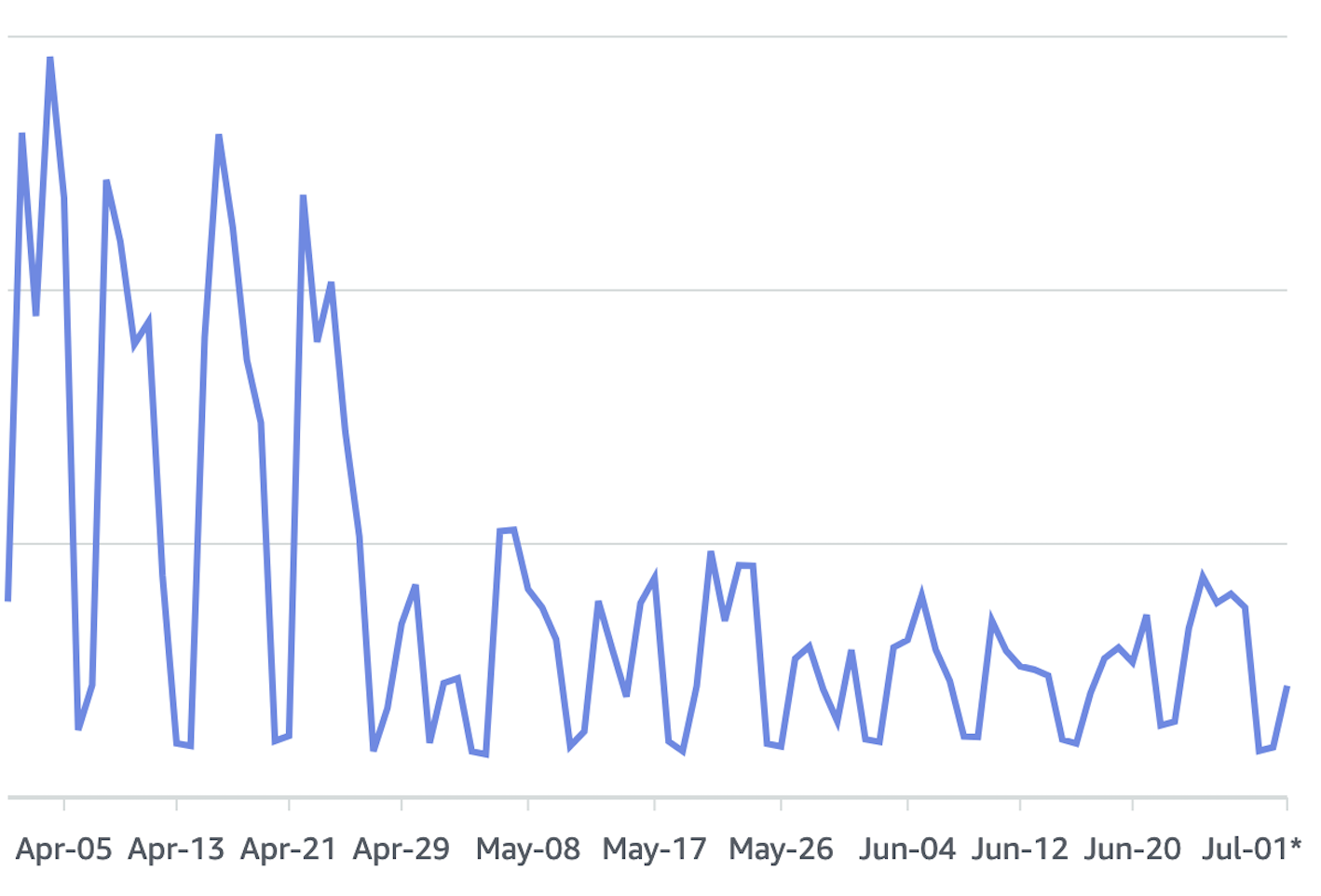
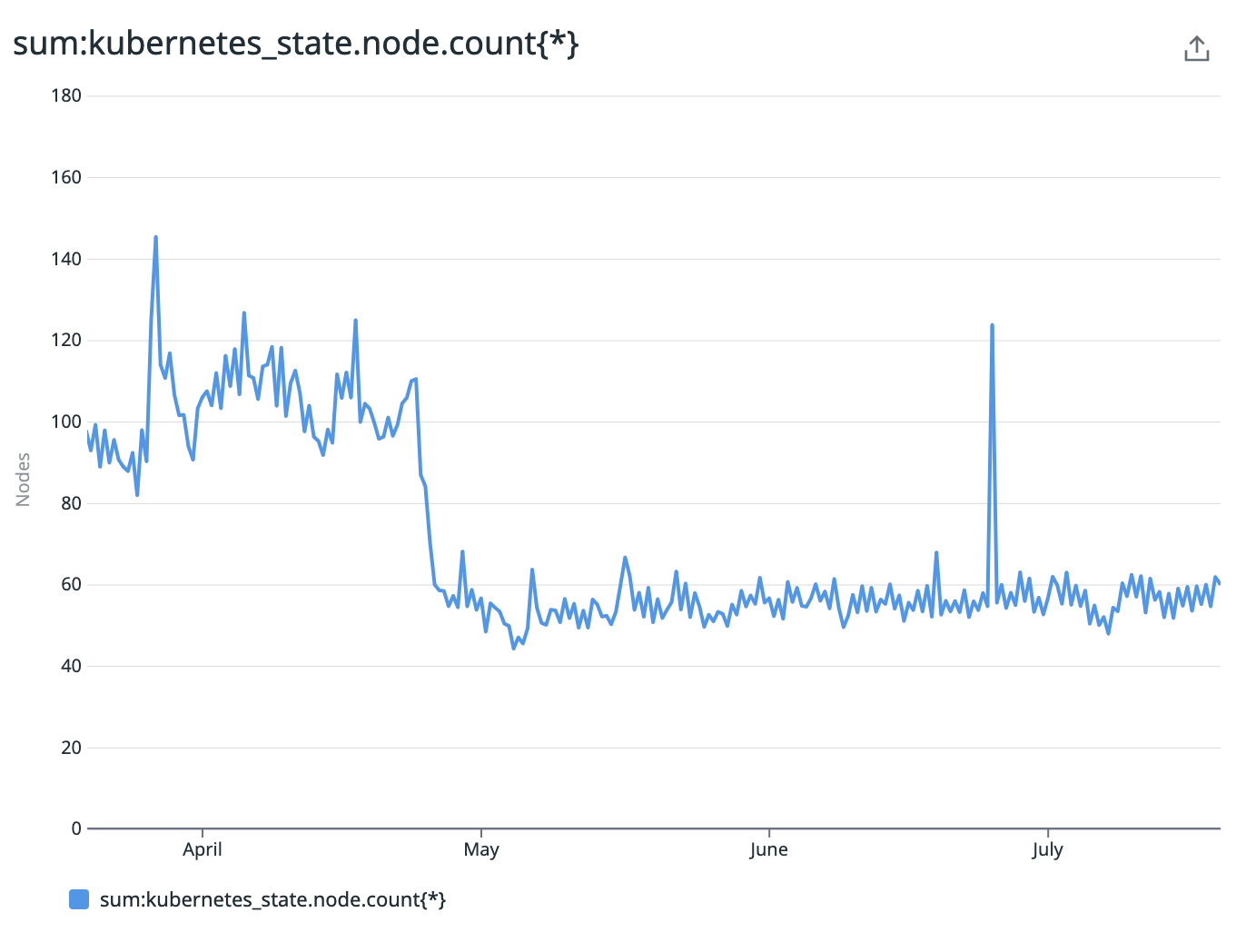
EC2 Usage Cost Savings
Our EC2 usage costs for the Kubernetes cluster have dropped by almost 50%. This was a surprise for us, as our goal was to save around 15%, but it exceeded our expectations.
The total number of EC2 nodes also decreased by a similar percentage.
Built-in Graceful Node Shutdown
With cluster-autoscaler, we had a Lambda function that would trigger on the lifecycle hook of the Kubernetes nodes to perform graceful node shutdown. The solution was flimsy and would often fail, causing node upgrades to result in 5xx errors for the pods that were running on the node.
Switching to Karpenter, which has built-in graceful node shutdown, allowed us to remove this custom solution, making our Kubernetes node upgrades faster and more resilient. No more sporadic 5xx errors during node upgrades!
Less Manual AWS Infrastructure Deployment
Karpenter uses a Kubernetes custom resource definition (CRD) to define the EC2 nodes. This means that we don’t need to define any AWS infrastructure manually, like Autoscaling Groups or Launch Configurations.
Karpenter made us get rid of a lot of CloudFormation templates and code, simplifying our cluster deployment pipelines and improving their runtime.
The Bad
Pods with Long Startup Times Are Affected
The way Karpenter optimizes the resources means a lot of pod evictions. The pods are killed on one node and then started again on another node. Pods that have long startup times and pods that don’t completely have their startup optimized are affected by this.
This issue was not apparent with cluster-autoscaler, as the pods would only go through this process when the nodes were being upgraded to a newer Kubernetes version. Any errors or issues during this time would just be blamed on the Kubernetes upgrade, masking the real issues that come from problematic application startups.
Karpenter brought these issues to the surface. We took the following actions to make the issue less severe:
- We made Karpenter less aggressive by utilizing the
disruption budgetsof NodePools. We configured it to only disrupt 1 node at a time, giving applications with startup issues a little more breathing room. We are still experimenting with the disruption settings, and we wish there were more resources on this topic. As of our last check, we didn’t find any threads or articles on this issue that might come with Karpenter. - We refactored our internal documentation on how to set up application health checks properly. Optimizing pod health checks resolved the startup issues for some applications. The most common problem was that the health checks were too fast, making them fail before the application had done its warmup procedure. A common change that applications had to do was to increase the
initialDelaySecondsparameter, allowing for more time before the health checks start. - For some applications, the startup issues were the cause of bad architecture or inefficient code. We got in touch with the application teams and explained to them why they were now facing these performance issues. We also helped them identify bottlenecks in their application architecture in order for them to come up with an actionable plan to optimize it.
More Errors Related to Daemonsets
Your daemonsets should be the first and last citizens on a node. This means that during node startup, daemonsets should be ready on that node before any application pods are scheduled. Similarly, during node shutdown, daemonsets should be the last to be evicted.
This might seem like common sense, but it is easy to overlook this if you don’t have regular node startup and shutdowns. Having an error related to a daemonset once every few months was within the SLO error budget with cluster-autoscaler. With Karpenter, however, a lot more nodes are being killed and started, which means the sample size for errors increases, and as a result, the total errors increase.
We had to revisit our daemonsets, adding startup taints and tolerations and also optimizing their shutdown process with graceful shutdown periods and lifecycle hooks.
Observability Costs Increased
This depends on the observability platform you are using and how the metrics and tags are billed. At Autoscout24, we are using Datadog. Anyone who has used Datadog before will know that custom metrics are expensive.
Karpenter adds a couple of tags that are mandatory for it to work. An example of this is the nodeclaim tag, which is a unique identifier for every node that Karpenter spins up. Since it is unique, and the total number of nodes that get spun up every day is huge, the cardinality of this tag is also huge. In Datadog, for every metric that gets tagged with this tag, a new custom metric is created. This means that the costs of observability increased.
How to solve this depends on the observability platform you are using. Unfortunately for us, since the tags are on the EC2 instances, we couldn’t filter them out at the Kubernetes level. To counteract these additional costs, we are looking into filtering out unneeded tags from within the Kubernetes cluster.
The Neutral
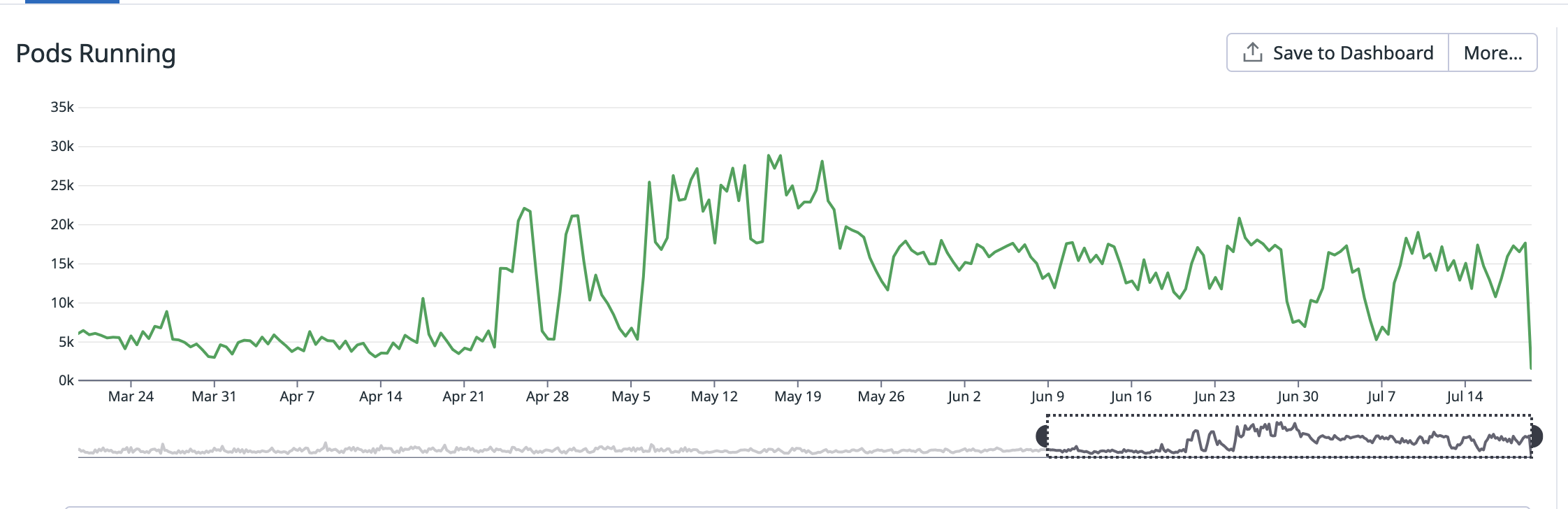
Total Number of Pods Increased
This is a natural consequence of having more pod lifecycle events because of Karpenter’s compute optimization. Pods are killed and started, performing their startup and shutdown procedures which take time. This means that at any given time, there are more pods running than before Karpenter.
The magnitude of this problem also depends on how tight the pod disruption budgets are. With smaller budgets, it will take more time for the pod eviction to complete, resulting in a higher total number of pods. With bigger budgets, the pods will be evicted faster, resulting in a lower total number of pods.
This has no significant impact on costs, as the only thing that gets billed is the node usage. It also has no impact on performance, as the pod disruption budgets make sure that enough pods are running at all times.
Conclusion
Overall, we consider our migration to Karpenter a big success. The EC2 cost savings alone are enough to justify it. The negative points mentioned in this article are not showstoppers, but rather things that we (and our developer teams) had to revisit and optimize.






