Modernizing our Data Platform - DataRunner
Aleksandar Marjanovic and Eloisa Hernandez · September 25, 2023 · 7 min read
At AutoScout24, we have a lot of valuable data. Despite this, data users such as engineers and analysts were having difficulty accessing it, transforming it, and making it available as a high-quality product for themselves and others. The Data Platform Engineering team set out on a mission to elevate the ease of use of our Data Platform and the quality of our data. We decided to create a true self-service data platform. The goal was not only to empower technical users but also analysts and other less technical team members to create data products that would unlock insights and more value from data.
A critical piece of this Data Platform is our transformation and processing tool. Our legacy tool had dependencies in outdated systems, and was difficult to use. When we measured the NetEasyScore, we got an underwhelming –20 (NES measures how easy a tool makes it for users to achieve their intended purpose on a scale of –100 to 100). So, we clearly had a big opportunity, so we kicked off our product discovery.
Product thinking for the Data Platform
In the last few years, the modern data stack has grown immensely. With so many solutions and vendors in the market, it is easy to be influenced by sales pitches and promises of solutions that can solve all of our data problems in one go. However, we knew that the only way to build a solution that provided value in our specific context was to listen to our users and ensure that what we chose aligned with our internal product principles and business goals. We wanted to ensure ease of use, cost efficiency and avoid getting locked into a single vendor.
Luckily for us, we had our users sitting right next to us! Data Scientists, Data Analysts, and Data Engineers all had so much to share, and we were thrilled to listen. With the support of an AWS Solutions Architect, we embarked on a discovery process to modernize our Data Platform. We built a Proof of Concept and performed discovery workshops to identify their needs using the Jobs to be Done methodology.
When we started the journey, we had so many assumptions (we should just use dbt, we only need to enable SQL users, etc.) and the proof of concept really helped us challenge those assumptions. We quickly discovered that we needed to enable users to use python as well, as they often had dependencies on external APIs. We also recognized that there were several use cases which depended on different data sources, so we needed to enable a connection to BigQuery and other databases.
At the end of the discovery, we had validated our proof of concept with our users, and we knew that our solution was feasible. We wanted to build a modular tool that would abstract complexity away from users, while helping ensure consistency, security and governance by supporting “Policies as Code”. Users didn’t need to know how everything worked under the hood, they would just provide a configuration file and the transformation code, and we would take care of the rest.
Enter… DataRunner (or what we built)
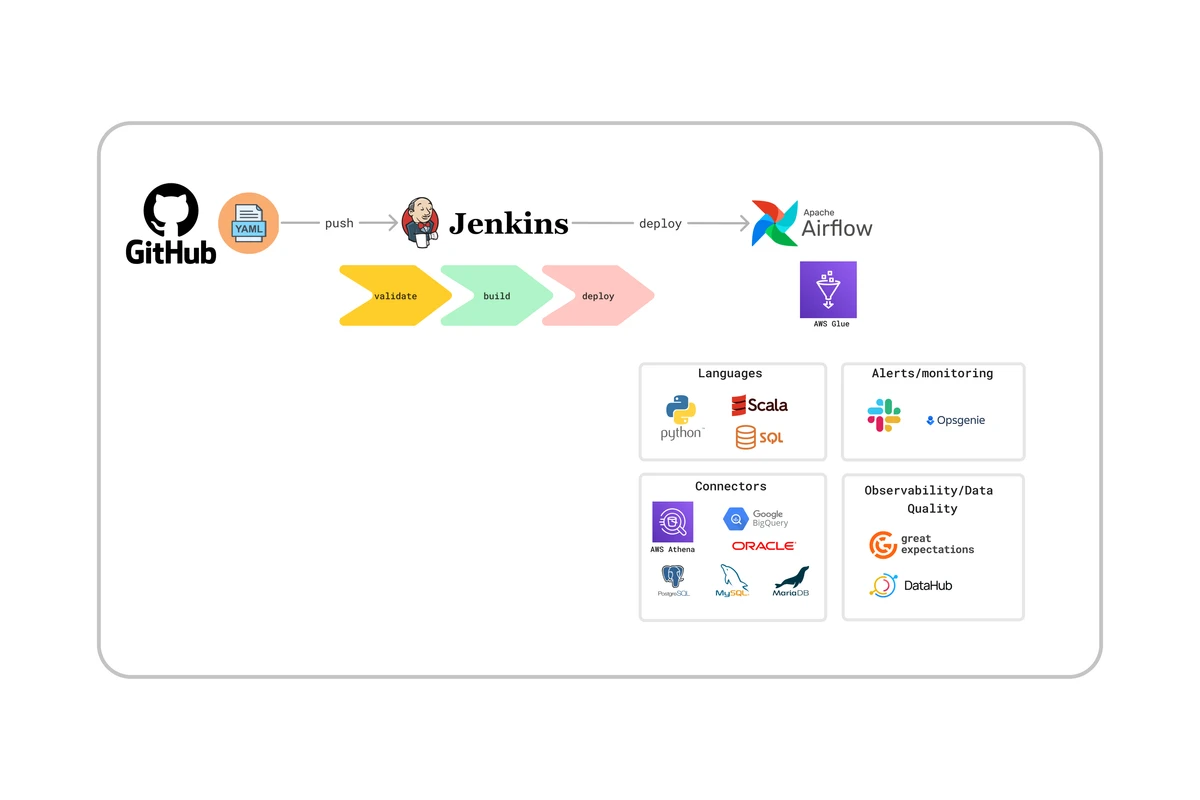
DataRunner is a tool conceived to offer a comprehensive solution for streamlined data processing and it is built with a robust tech stack comprising AWS Glue, AWS Athena, Airflow, Git, Jenkins, Python, PySpark, and integrated with DataHub, and Great Expectations. It promotes decentralized ownership, governance, and access to data while ensuring that security measures are implemented at each step of the data processing workflow, safeguarding sensitive information and adhering to regulatory requirements.
Users interact with DataRunner via a Github repository where they only need to go through two steps for most cases. These steps are: 1) Enter metadata used for governance, security and transformation configuration in a .yaml file, and 2) provide the transformation code according to their needs. This code can be Python, PySpark, Scala or SQL.
Once users push their code changes to the designated repository, DataRunner ensures seamless deployment through a simple and efficient process. It leverages the power of Git and Jenkins, triggering automated builds and deployments. On Git push, there is a validation step that runs tests, and other checks so there are no unexpected errors on runtime. This step also enforces our security model to guarantee security and regulations compliance. This streamlined deployment process saves time and ensures that the latest code changes are deployed consistently across different environments.
Once the code is deployed and validated, DataRunner defines and schedules pipelines in Airflow as directed acyclic graphs (DAGs) based on the configuration provided by the user. Airflow is crucial for orchestrating complex data processing workflows. With Airflow, DataRunner enables users to easily define dependencies between different data processing tasks, ensuring smooth execution and efficient resource utilization.
At the core of DataRunner’s data processing capabilities lies AWS Glue and AWS Athena. AWS Glue enables the extraction, transformation, and loading (ETL) of data, automating the process of discovering, cataloging, and transforming data sources. With its scalable and serverless architecture, AWS Glue simplifies the complex task of data preparation. With AWS Athena, DataRunner gains a powerful engine for the ETL load step by seamlessly querying the data directly from Amazon S3. AWS Athena allows DataRunner to efficiently process large-scale data without the need for complex infrastructure management or data loading. By integrating AWS Athena alongside AWS Glue, DataRunner’s data processing pipeline becomes even more streamlined, enabling quick and cost-effective data analysis on the transformed data, ultimately accelerating insights and driving smarter decision-making.
DataRunner offers support for various connectors, including BigQuery, MySQL, MariaDB, Oracle, and DynamoDB, enabling seamless integration with different data sources. This flexibility allows users to access and process data from diverse systems and databases, making for a versatile tool for organizations with heterogeneous data environments like ours.
Finally, in order to facilitate and enhance data discoverability and enable data quality, DataRunner integrates with DataHub and Great Expectations. DataHub allows users to discover and collaborate on data assets by providing a unified metadata repository. Great Expectations, on the other hand, enables data validation and monitoring, ensuring the accuracy and reliability of processed data. These integrations empower users to maintain data quality, track lineage, and collaborate effectively on data-related projects.
DataRunner is a powerful data processing tool that empowers data users to create robust datasets that are discoverable, secure, understandable and trustworthy, getting AS24 closer to a culture of “data as product”.
What’s next
We have seen a lot of enthusiasm and good adoption of the tool and we have received good feedback (NetEasyScore for v1 is 22 - Good). So far, besides engineers, we have empowered data analysts, product analysts and even a product manager to use the tool to unblock themselves and create their own pipelines and tables.
We are also in the process of identifying all the data dependencies for the top KPIs we use to make business decisions. We want to focus data that represents the health of the business to improve quality and increase trust. To that end, we will leverage DataRunner to implement quality checks and discoverability. We know there’s a lot more to do and that DataRunner will keep evolving. At the same time, we know that as long as we keep listening to our users and focusing on delivering value, we are on the right track to leveraging our data even more to steer forward our business.







