Good patterns and hints for incident resolution at AutoScout24
Bayram Kiran · September 21, 2022 · 7 min read
Introduction
Hello there folks, here is Bayram. I’ve been working at AutoScout24 (AS24) since 5 years and I worked in 3 different teams within that time. In my most recent position, I became more of a tech lead which led me to be involved in more incident resolution processes. I must say, I think we at AS24 generally do a pretty good job in mitigating and resolving incidents, however what I noticed is that sometimes maybe the resolution could have been quicker if the people knew some features in the tools/infrastructure (jenkins, aws) involved or they had a better focus on the resolution.
Let us start with giving a definition for incident. I found a nice definition on this gitlab page and adjusted a bit:
Incidents, in context of information technology, are anomalous conditions that result in or may lead to feature/service degradation or outages. These events require human intervention to mitigate disruptions or restore service to operational status.
Incident management
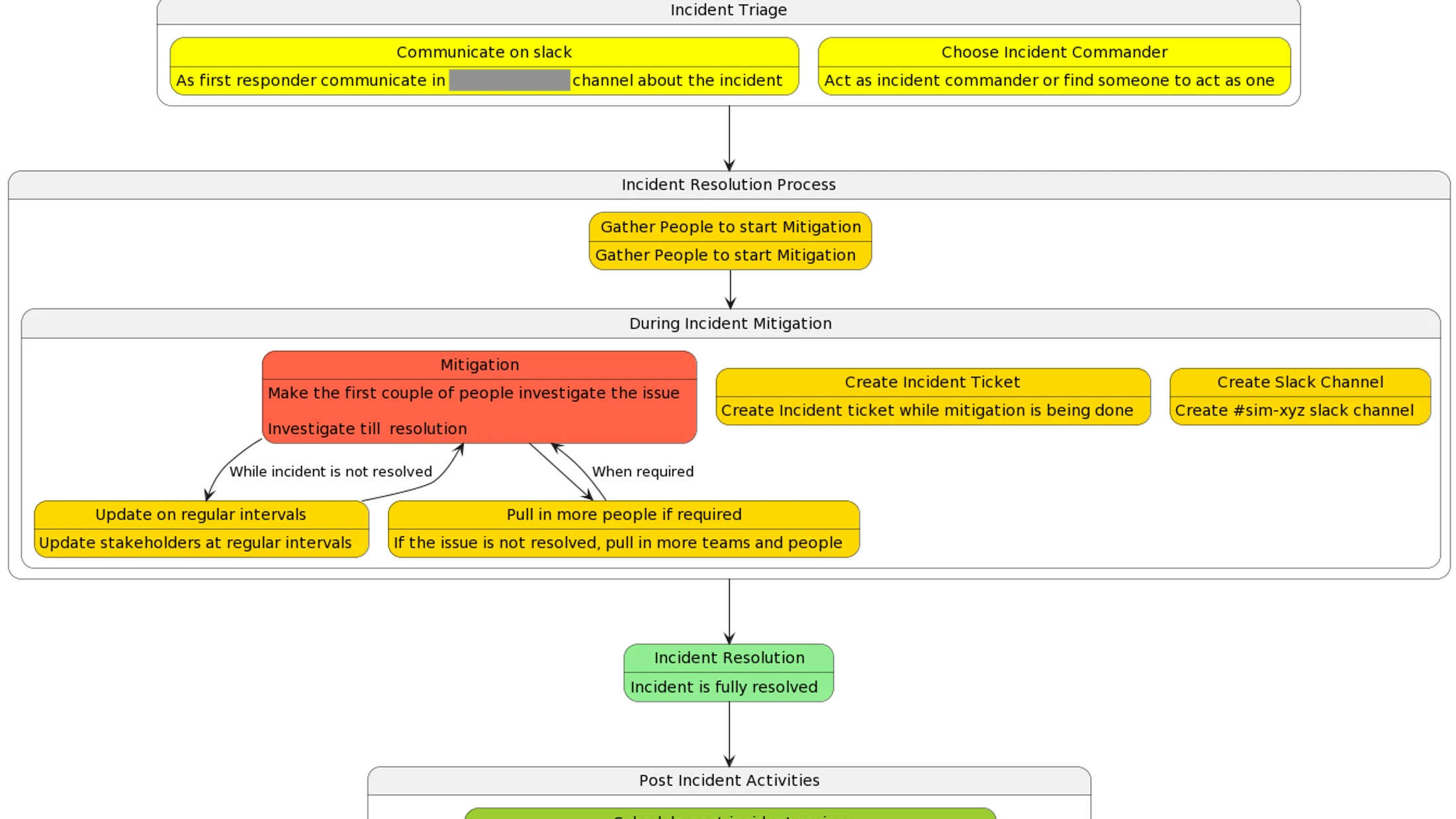
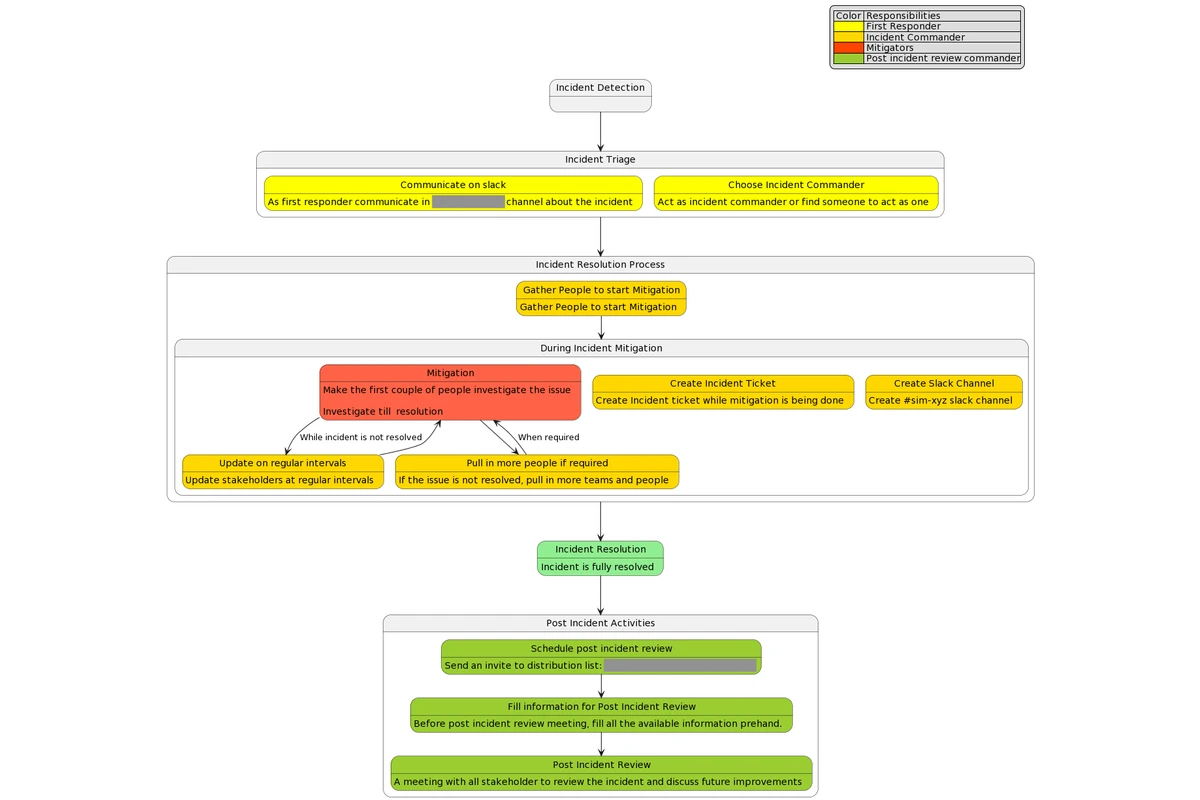
I’m lucky in that we have so many brilliant people who have already worked on this topic, producing amazing documentation and flowcharts (see one below). However, I’ll still go over a couple of points which I think are quite important to mention one more time.
- Post the detected issue in the company incident channel and tag/mention the people who might be able to help or would be interested in resolution. This is very important because this is the quickest and the most impactful action one can do to communicate and get help quickly from people. In ideal case, there will be someone assigned as the incident commander who will take care of creating necessary tracking tickets, communicate updates and pull in more people when needed.
- Although the process around incident management and communication is very important, it is still less important than resolving the incident. So if there is no capacity for both tasks (make sure to do your best in finding an incident commander), you should focus on resolving the issue first. Everything around communication and tickets can be achieved later.
- Create a videochat with the people who are involved in resolving/mitigating the issue. For such an urgent usecase, written communication is not efficient enough.
Focus on rollback/mitigation not fixing forward
It is only natural that people get curious on what is actually broken, how it is broken and how to fix it because we as humans are curious beings and attracted to investigating/fixing things. However, this trait can be quite counter-productive because it leads people to think/focus on fixing forward the issue instead of mitigating the issue asap.
As an example, let’s assume the issue was introduced by a code change in the application.
- Person looks at the pull request to see what part of the code can cause the issue.
- Instead, they should actually focus on rolling back the previous version of the application.
Rolling back is almost always the more straightforward, quicker way to mitigate the issue. Fixing forward should be the last resort, only if all options to roll back are examined and seem not applicable.
Rolling back/Mitigation options can be things like turning off a feature toggle, deploying a previous version of an application or manually scaling up an AWS Auto Scaling group.
Deploying the previous version as quickly as possible
This is the most common mitigation method especially if the issue was caused by a code change. I see most people actually apply this method to mitigate but sometimes they run the whole CI pipeline to deploy the previous version which can take around 20-30 minutes (or in some cases even longer). We at AS24 are lucky to have our CI infrastructure/tooling setup in a way that we can deploy the previous version directly without needing to build the app or publish the artifact since we save the previous application deployable artifacts in AWS ECR. Thanks to that, we can make use of Jenkins’s feature to run a job from a stage (deploy stage) so that deploying can be done within a few minutes. See the instructions below on how to do this:
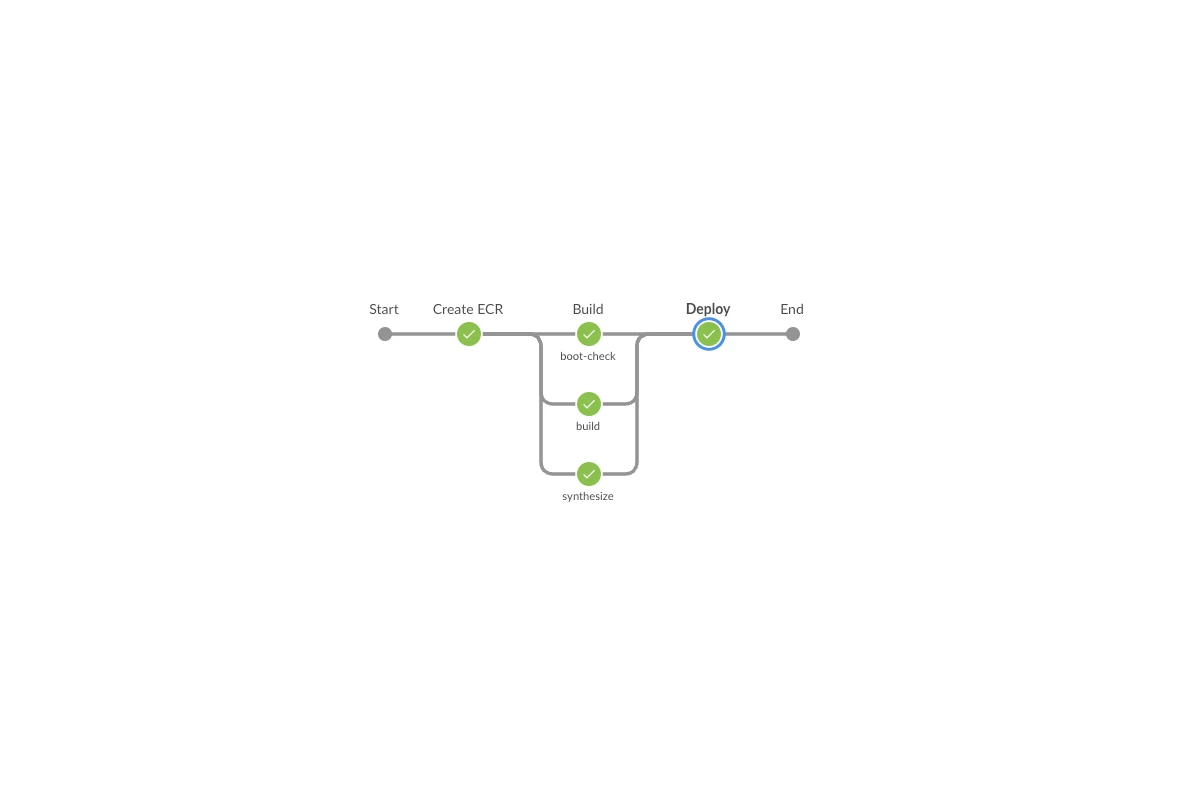
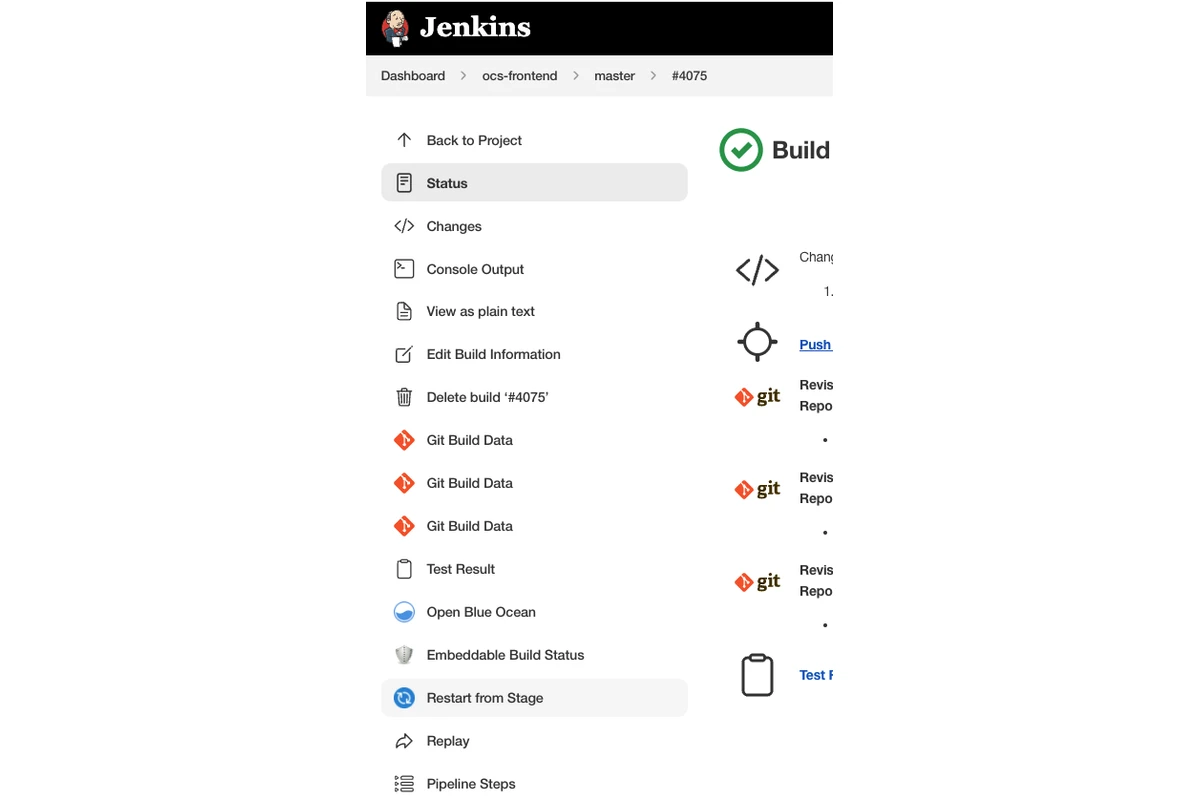
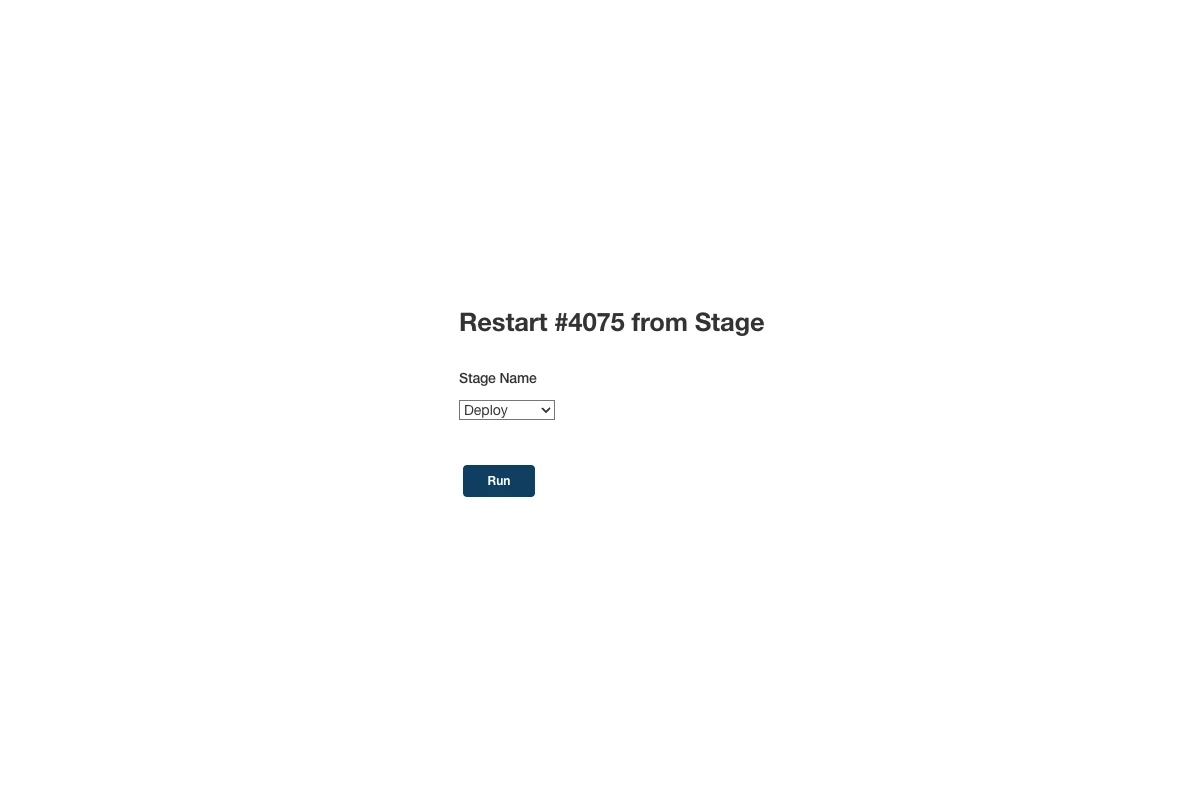
You can find more information about this feature here on the official Jenkins documentation.
Important Reminder: If you deploy the previous version via Jenkins, do not forget to create and merge (you don’t need to wait for the CI if there was no commit done to main branch after the buggy PR commit) the revert PR for the original buggy PR, therefore the buggy version is not deployed again by accident.
There is also another Jenkins feature which could be useful in certain usecases (maybe skip a stage which takes too long and not necessary at that point) when you’d need to modify the jenkins job definition on the spot and quickly. The feature is called Replaying a pipeline and it is explained pretty well in the official Jenkins documentation.
Direct actions in AWS
At AS24, we use AWS CDK and define our infrastructure via typescript code. We then use aws cdk synth utility to create AWS CloudFormation (CFN) stack definition and deploy that stack through jenkins + AWS CFN.
This setup works pretty well for the regular daily product development. On the other hand, sometimes during incidents going through the whole toolchain may not be the more efficient method to do changes in the infrastructure especially during high-impact/time-critical incidents.
Let’s have an example scenario to clarify. Let’s assume that, the load of our service went up quite a bit and our application servers couldn’t handle the load and started dying. AWS Autoscaling wasn’t quick enough to boot up new instances to support the additional load. In such a usecase, we might want to increase the minimum capacity of our autoscaling configuration but doing it in the code and deploying it via Jenkins might actually take too long (20-30 minutes). Instead, we can increase the minimum capacity directly in AWS Web Console which I explained below:
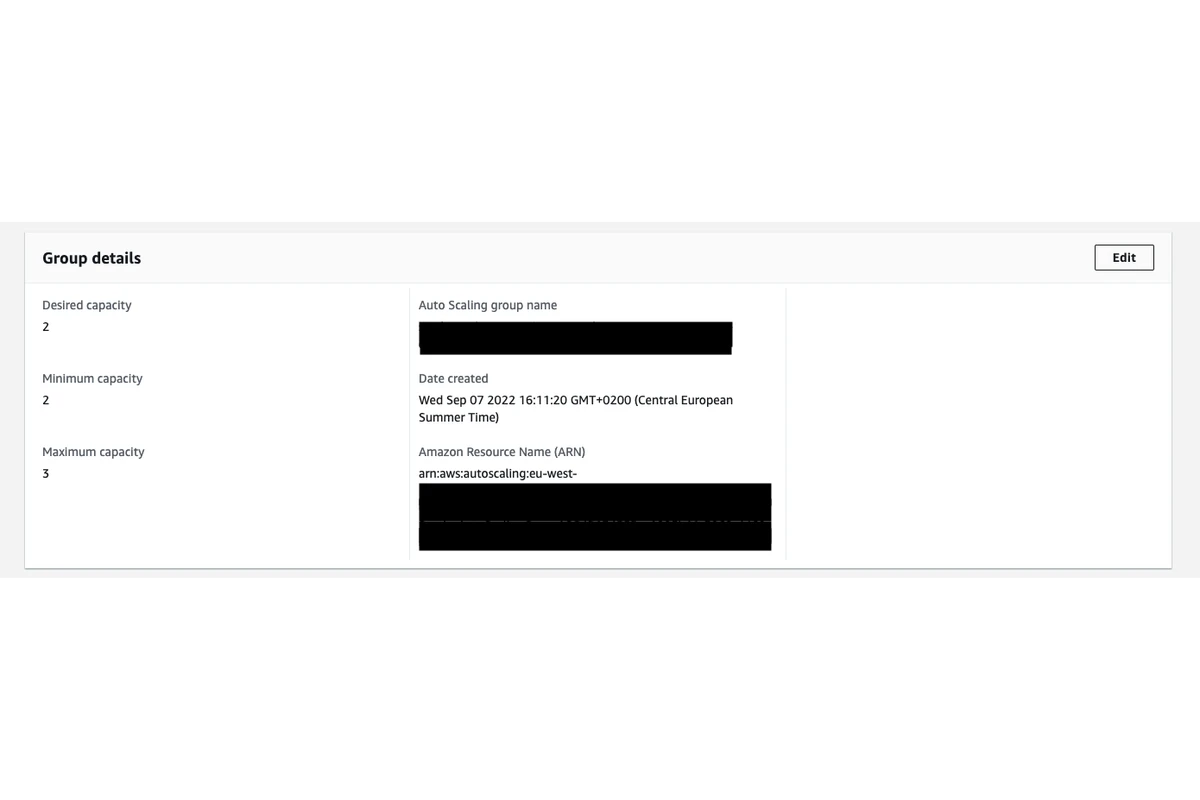
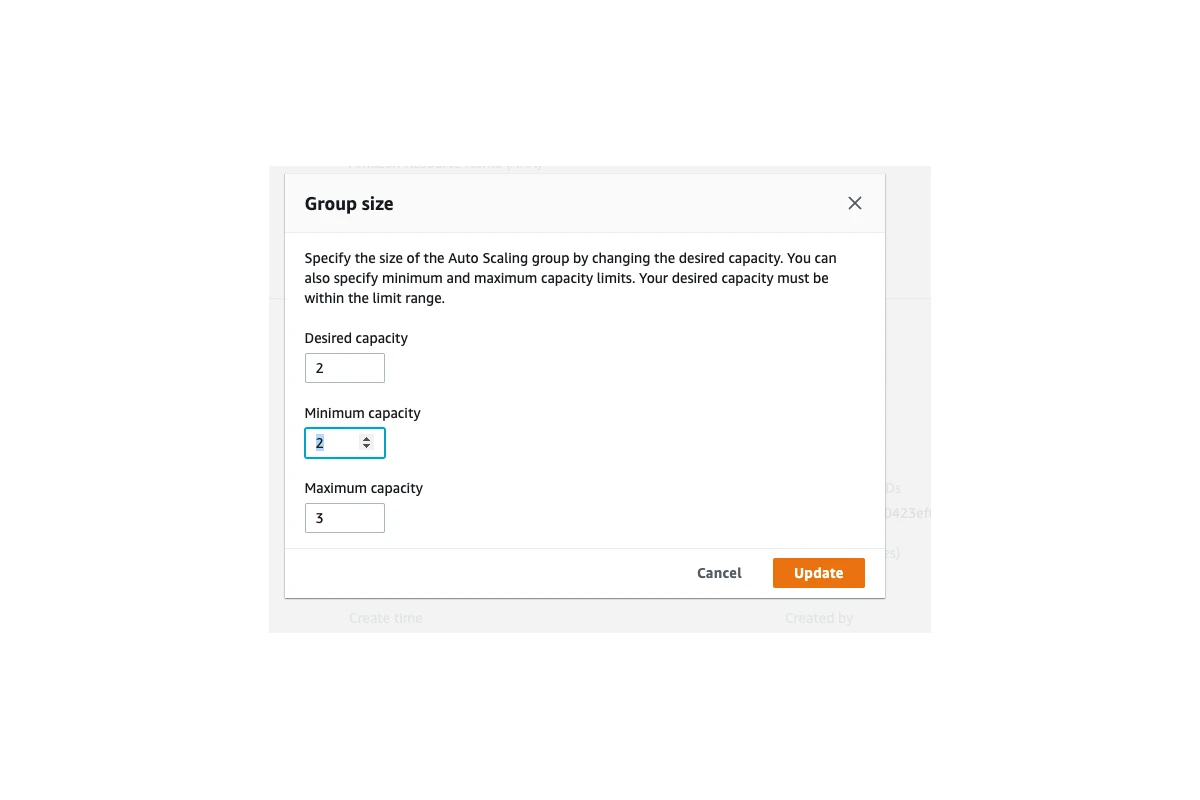
Logging in to EC2 machines
In some rare cases, a new deployment may not solve the issue or there may not be a direct application code change causing the issue. For those usecases, it could be useful to login to the server, play around and do some direct checks on the server (checking some logs or CPU/memory for example).
We at AS24 have AWS Session Manager set up for our EC2 instances, so that we can use it to login to the server directly in the browser (it’s also possible on command line) and do the required actions on the server. For doing that, you would first need to find the EC2 instance which you want to login, right click on it and click on Connect button:
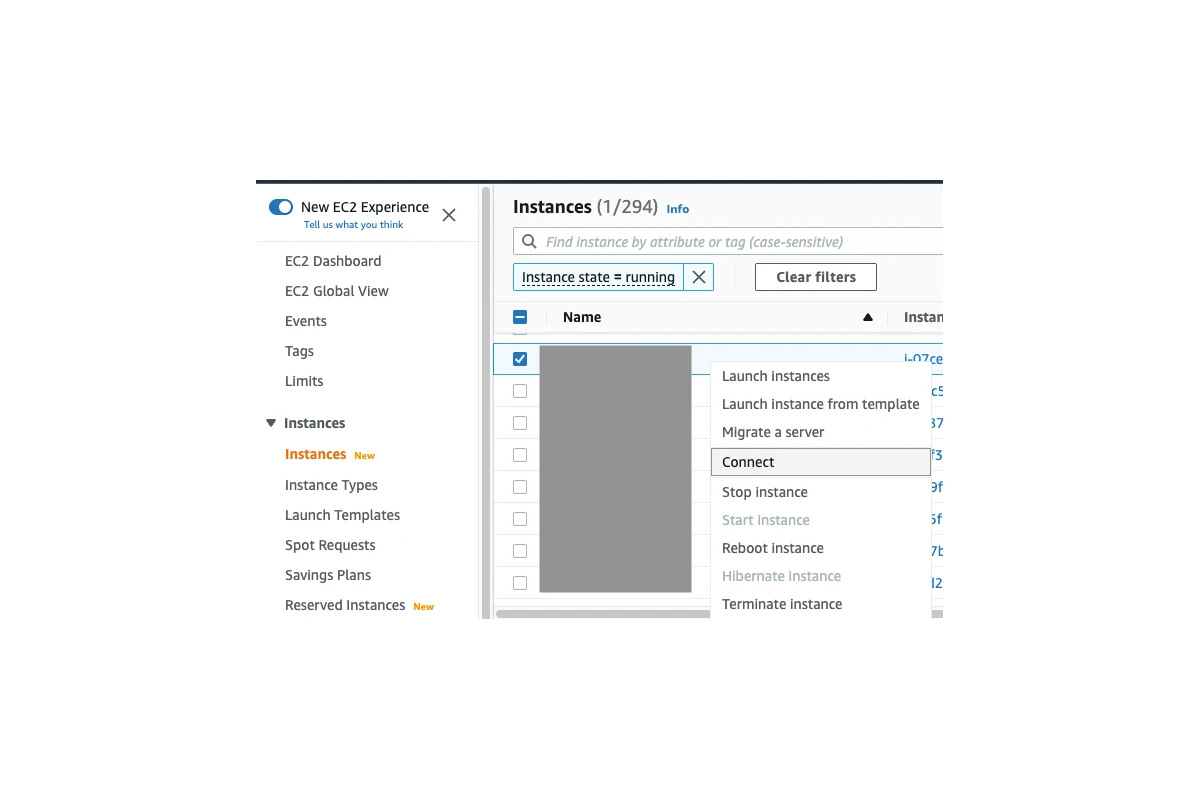
On the connect to instance page, you can switch to Session Manager tab and click on the Connect button:
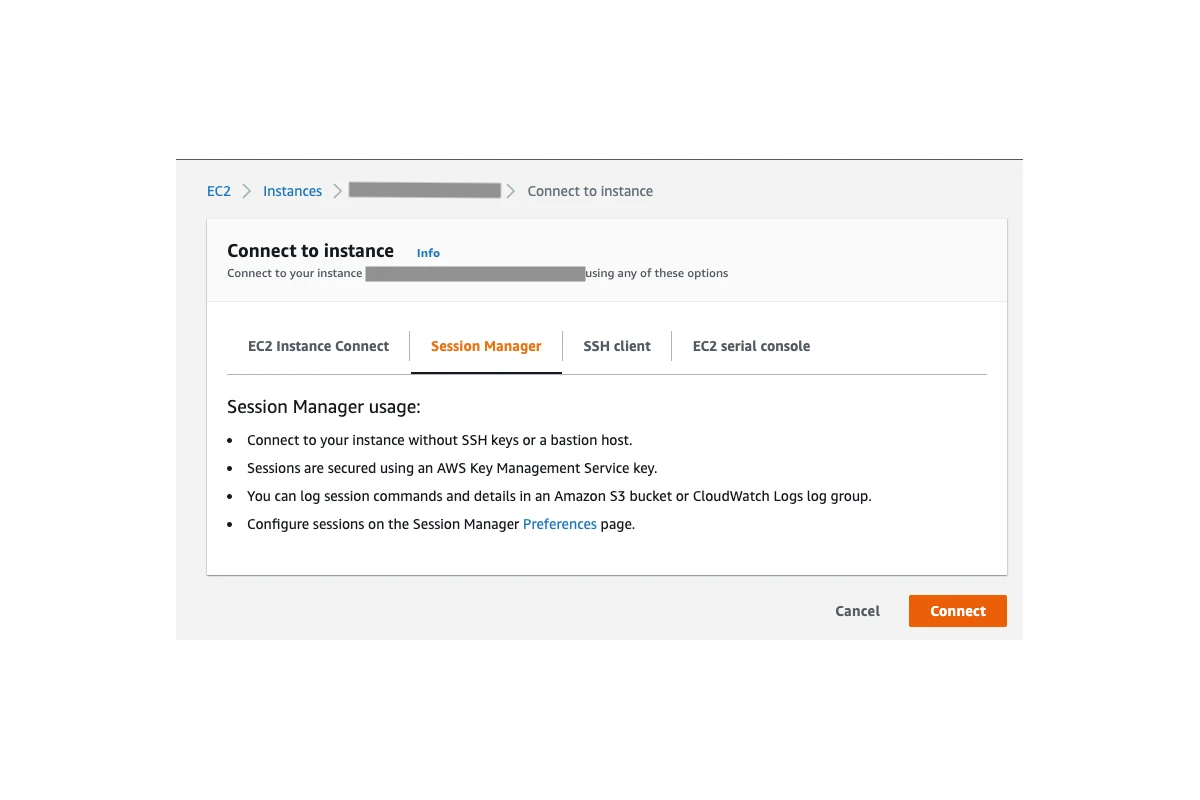
This will open a command line in your browser where you have access to the server. You can check some logs,

or check CPU and Memory usage:
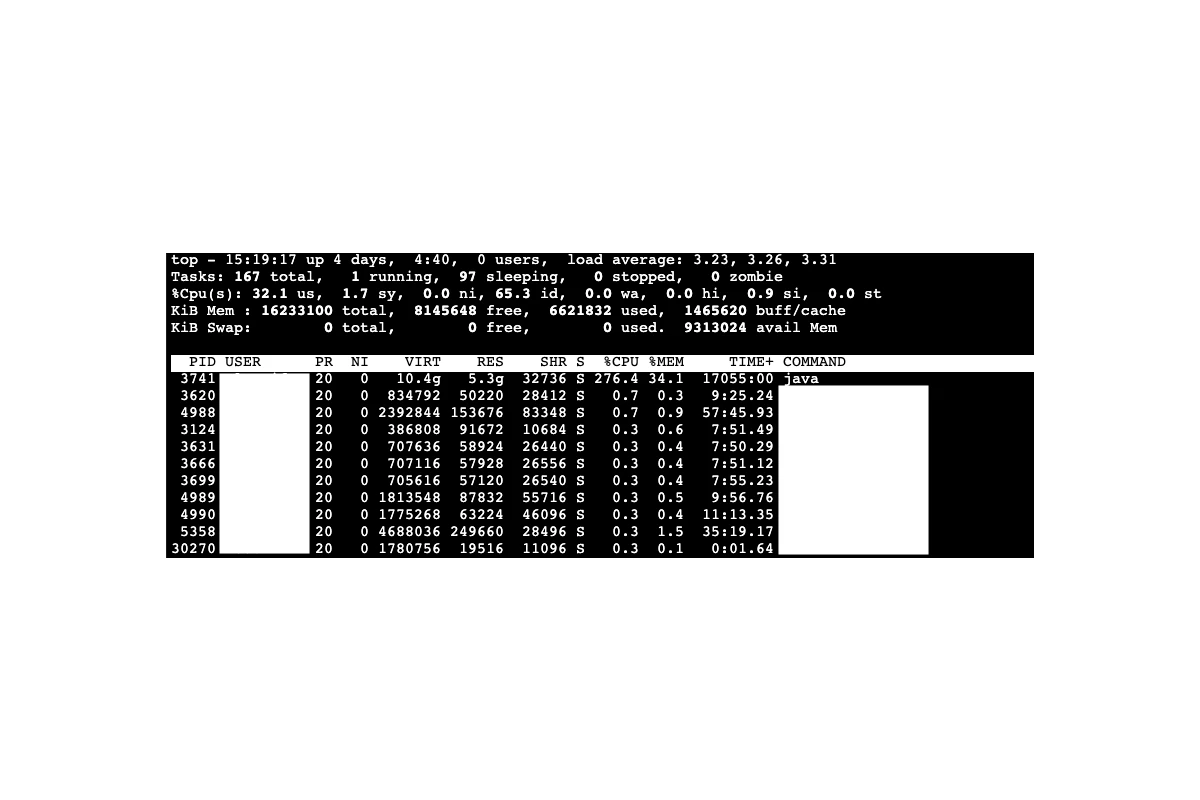
or do any other actions which may be required depending on the issue.






