
A tale of testing AI in the wild - Our experience with automating internal platform support with a LLM bot
Arslan Mehboob · September 16, 2024 · 9 min read
I am a platform (DevOps) engineer at Autoscout24. What is that you may ask? Making sure our platform (a bunch of code in the cloud) enables other software engineers to build and run their code in the cloud.
The support includes answering technical questions. Sometimes weirdly specific, other times I have to spend hours scanning through docs and google just to understand the context. Sometimes, things catch on fire (metaphorically, usually), and our team help put it out. This is done mostly on slack.
Our platform is basically a toolkit for writing, building, deploying, and running software without everything crashing. We’ve got internal docs that (hopefully) explain how it all works.
What we wanted to do:
1. Provide faster support to software engineers:
Software engineers are impatient creatures. Disrupting the flow is a dangerous thing in the software world. A small blocker takes the engineer to open reddit, which leads to youtube and then its game over.
2. Ease burden from support from platform engineers:
The less time spent in support translates to more time improving the platform (at least that’s what we want the management to believe).
What we did?
LLMs have been the bees’ knees lately. So, one fine day, we put our heads together, did some complicated 2+2 math, and decided it was a worthy adventure.
What is required to solve this problem?
Some way to index data, in this case our internal documentation.
Some tooling to hook slack with a LLM. So the users can use the existing medium of communication.
RAG (Retrieval Augmented Generation) support. This requires storing/retrieving to/from a vector database.
Some way to control the question/answer flow.
Danswer
In order to not reinvent the wheel, we set out to look for some existing tooling that could kickstart our quest for LLM adventures. Danswer was the answer to this short research. Danswer is an open source project that does exactly what we needed. Danswer provides out of the box support for deploying in AWS, which was perfect for us. One t4g.xlarge instance was good enough to handle everything.
Index the knowledge base:
Danswer provides a way to index multiple sources of information. For our case an inbuilt web connector did the job of ingesting and indexing the data in a vector database (Vespa). We hooked the connector to our internal documentation along with some publicly available documentation from AWS.
Hook to a LLM:
The second step was to hook a LLM to danswer. Here, we used AWS bedrock. If you don’t know much about bedrock. think of it as a one-stop shop for LLMs. It’s like a managed service that wraps up a bunch of different models and hands you a standard API to play with them all. Pretty neat, right?
For our use case, we went with Claude Instant. Why? Well, it’s fast, it’s cheap, and it gets the job done (mostly).
Slack Integration:
The third step was to hook our slack support channel with Danswer. Which is supported out of the box in Danswer.
Tweak System Prompt:
The final and the most important step was fine tuning system prompt and announcing the bot to our users. The system prompt is like the core ingredient in refining the responses. Being the non deterministic nature of the problem, improving the prompt is an iterative process and can take some time to nail it down. Here is the system prompt that we ended up using. Which is still not perfect but it’s a good start.
You are a software developer assistant. Your goal is to provide the most accurate answers possible to software developers. Use concise language without giving extra details. Add the most informative part of the answer as a TL;DR at the top.
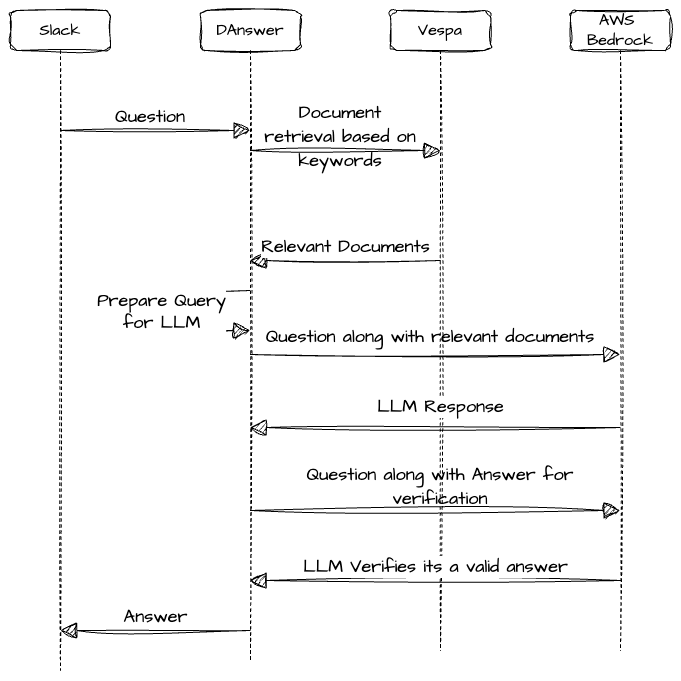
Here is how the question answer flow looks like.
Challenges we faced:
Problems with Documentation
Software engineering is a creative profession. One of the biggest challenge in software engineering is managing the complexity of the systems. That’s where platform engineering comes in, it’s like the conductor in an orchestra, keeping everything in harmony through standardization.
We control this complexity with a collection of common standards, protocols, and tools. However there is a tradeoff at play here. Too much standardization, and you end up with a platform team buried in overhead, while developers feel like they’re wading through quicksand. Not enough, and you’ve got chaos. So, we have to find that sweet spot where teams are self-sufficient, able to move quickly and independently.
The self-service nature of our platform is key to this balance. Good documentation forms the backbone of self-service, but here’s the catch: documentation is static. It can’t possibly cover every weird edge case or scenario that might pop up. A good support bot relies on the training data and in this case the data has limitations due to these aspects.
 |
|---|
| https://geekandpoke.typepad.com/geekandpoke/2012/04/the-new-developer.html |
Static nature of documentation:
Engineering problems require a context and often require logs and metrics to troubleshoot. There is a bug for example that breaks existing functionality. This requires LLM to have real time picture of the environment which frankly is way more complicated than it sounds.
All docs are equal but some are more equal than others:
Our system has indexed multiple sources of information. We use AWS as the cloud provider so indexing their docs was a natural choice. However we wrap a lot of functionality over AWS and prefer to use those abstractions. And you guessed it, we want to present our solutions when given the chance. With Danswer it was not possible to do it.
Not everyone has access to same knowledge:
Different authorisation levels may abstract away some information from some users. It is not possible to do this in Danswer.
Contextual tradeoffs:
There are multiple right answers to a question, often times different tradeoffs need to be considered depending on the context.
Stopping AI to not answer
By default, every LLM will try to answer every question, even if it has no clue what it’s talking about. If you’re lucky, it might admit it doesn’t know the answer. But in engineering (and probably in most cases?), a “no answer” is way better than a wrong answer.
The problem is, LLMs have a tendency to hallucinate. They’ll confidently generate responses that sound plausible but are completely off the mark. And fixing this? Not exactly easy. We couldn’t solve it entirely, but we did manage to dial it down a bit with some clever tricks.
We used a multilayer approach here. Think of it like adding a series of filters or checkpoints before the AI’s response reaches you. Each layer is designed to catch potential nonsense before it makes its way into the conversation. It’s not foolproof, but it helps cut down on the more creative (and completely inaccurate) answers.
Validate the question is relevant:
With some experimentation we found out that some questions are not suited for LLM. Here is a system prompt that helped reduce irrelevant answers.
If the question is about a pull request reply with "Sorry I cannot help with this request". If the question is about something that is not related to software development then reply with "Sorry I cannot help with this request". If the question includes a hyper link then reply with "Sorry I cannot help with this request".Validate the answer is helpful:
Danswer comes with a nifty feature called “Reflection.” Basically, it lets you send the answer back to the LLM along with the original question to see if it thinks it gave a good response. In short, it’s like asking, “Are you sure?”
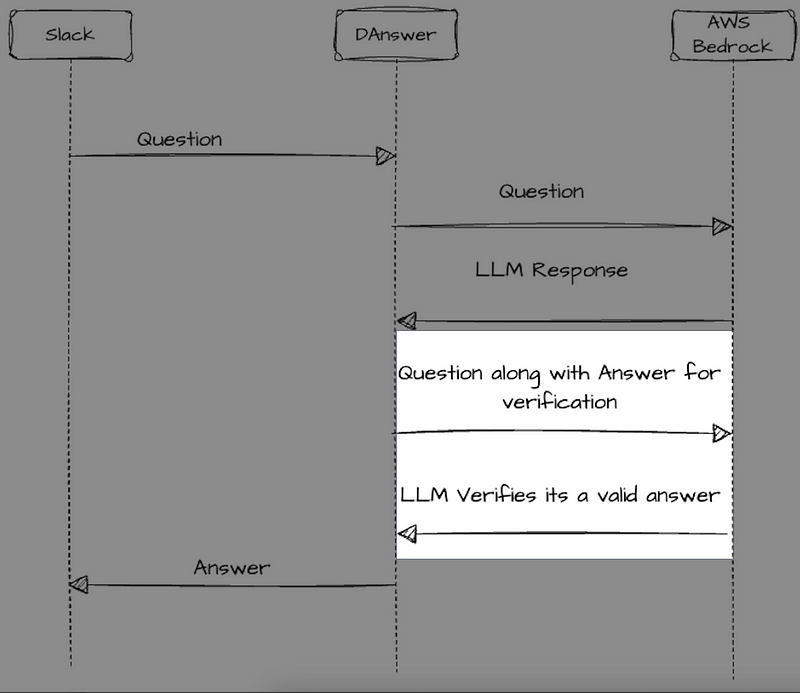
This is a brilliant way to control the quality of the answers. However, it’s not without its own quirks. The issue is that asking the same LLM to verify its own answer almost always results in a thumbs-up. It’s like asking a kid to double-check their math homework when they’re not quite sure how addition works—they’ll probably just say it’s right.
One idea we’ve kicked around is asking for validation from a more powerful LLM. In theory, this could yield better results since the bigger model might catch mistakes the smaller one misses. But, to be honest, we haven’t tried that yet. It’s on the list, though!
Another way to guide Reflection is by using a system prompt. This is basically a set of instructions you give to the LLM before it starts answering questions. Here’s the prompt we’re using:
System prompt to validate Answers
1. Answer addresses a related but different query. To be helpful, the model may provide related information about a query but it won't match what the user is asking, this is invalid.
2. Answer is just some form of "I don't know" or "not enough information" without significant additional useful information. Explaining why it does not know or cannot answer is invalid.Conclusion:
Reflecting back on the experiment, I’d rate it as mildly successful. The tooling provided by Danswer makes it really easy to set up and get things rolling quickly. Plus, since it’s open source, you have the flexibility to tweak and modify the functionality to fit your needs. The community is still growing, so you might not get all the answers you’re looking for, but there’s potential there. If you need more robust support, they do offer an enterprise version, which could be worth exploring. There is very little maintenance overhead, and the system is pretty stable.
If you’ve got solid documentation, this setup can work well as a first layer of support. It also opens up opportunities to spot gaps in your docs and improve them over time. Tinkering with the system prompt is straightforward, and you can fine-tune it until you get the results you want.
At the moment, the bot’s success rate in answering questions is hovering around 30-40%. We’re planning some improvements to bump that up to at least 60%, so stay tuned.
Future Improvements we want to make:
Add more weight to internal documentation when answering.
Stop non answers and hallucinations.
Educate on how to ask better questions.
Create a process to improve documentation where the bot could have used better knowledge.
Thanks for reading and stay tuned for the part 2 where we will cover our journey to improve the quality of the support.






